AI at Tyson Foods
The messy reality of AI adoption in the corporate world.

Foreword
In late 2024, I had the privilege of being involved in the first version of AskDEB — Tyson's internal generative AI application. However, the results weren't great: daily usage rates were very low. In early 2025, 6 months after the first release, we decided to revisit AskDEB, and thus began a journey of discovering the messy reality of AI adoption in the corporate world.
This is more of a snapshot than a case study. It doesn't have an ending yet — only stories to tell about what's currently happening, what went wrong, and how we can do better.
1. A Food Company Catching Up with AI
The story began when everyone started talking about AI.
As a food company, Tyson's strength had always been operational excellence, not technology advancement. But AI came and promised to help everyone in the organization, not just operations and tech teams. And the question became: how?
Well, the first step was to get everyone access to AI, and see how they would use it in their work. So the tech team built an internal AI app, AskDEB, to test the waters. AskDEB does 2 things: it has a chat interface that connects to APIs of popular AI models, and it adds a protective layer to secure access to internal data.
 [fig 1] Main Screen of AskDEB: very simple chat interface with LLM models.
[fig 1] Main Screen of AskDEB: very simple chat interface with LLM models.
2. The Problem
6 months after AskDEB launched, around 2,000 employees (roughly 30% of Tyson's corporate workforce) logged into AskDEB at least once. However, only 10% became daily active users.
To make AskDEB more useful and gain more users, the product team decided to revisit AskDEB entirely.
Through early stakeholder interviews, we found that different people had different theories on what was happening and where we should go:
- Tech leaders wanted to build advanced features for power users, hoping they'll evangelize to others.
- Higher leadership believed that people didn’t trust AskDEB because it’s not giving answers as good as ChatGPT.
- The UX team saw usability issues that can be fixed to make it easier to use.
- The product team thought that people don’t know how to use AskDEB, and they need more training.
And all those theories were just hypotheses. To understand what was really happening and gain consensus across stakeholders, we started our research journey.
3. The Research Begins
We planned our research in 3 phases:
- Initial Qualitative Research: we interviewed a small batch of users from different departments to get some initial findings.
- Large Scale Quantitative Research: with a large-scale survey, we can validate or invalidate our initial findings, and get more quantitive insights.
- Follow-up Qualitative Research: return to user interviews to validate and expand on the previous findings.
4. Initial Findings: Success Stories and Hidden Issues
From our initial qualitative research, we found some mixed feelings about AskDEB.
On one hand, we saw quite a few power users had already heavily integrated AskDEB into their daily workflows. For example, a chef from R&D (Research & Development) used AskDEB to accelerate brainstorming sessions. An IT manager built a multilingual chatbot that answers questions about complicated internal processes.
On the other hand, we also gathered lots of negative comments.
For example, users admitted they have “trust issues” with AskDEB and believed ChatGPT had better results. This was a mystery to us. AskDEB and ChatGPT were using the same OpenAI APIs, and the only thing that might go wrong was the UI layer. We were guessing that maybe it was the small UI details that made users feel differently.
Another major comment was about UX issues with current features. For example, AskDEB allowed users to switch between AI models. However, users didn’t care about the models until the result was bad. And when they did want to change, those model names meant nothing to them. They only cared about which models worked the best for their current task. This led to a quick design pivot: we displayed task categories instead of model names.
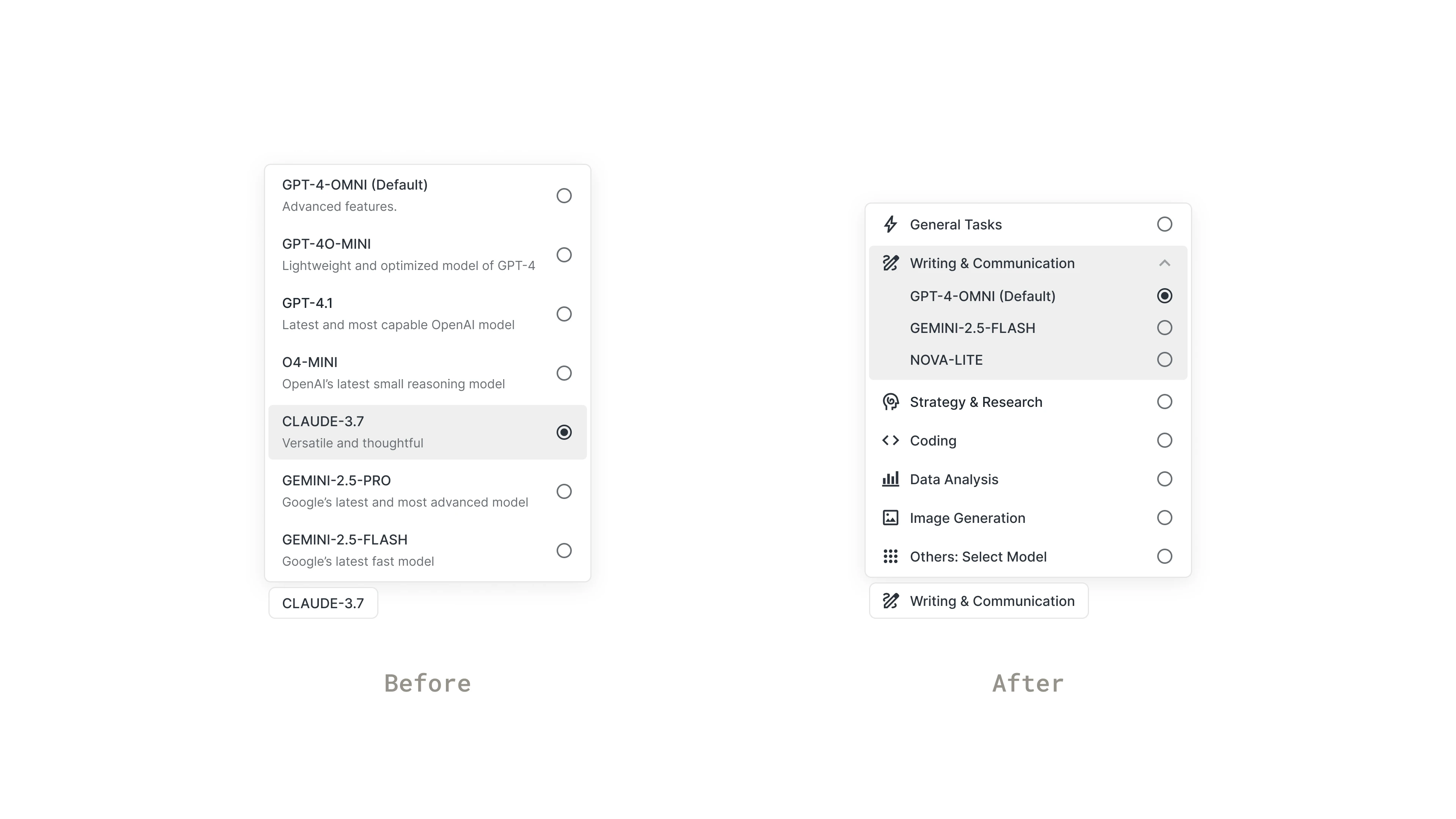 [fig 2] Before (left): displaying model names; After (right): displaying task categories that make sense to users.
[fig 2] Before (left): displaying model names; After (right): displaying task categories that make sense to users.
5. Deeper Investigation: A Large-scale Survey
Now that we had those initial insights from a few active users, we still lacked understanding on the non-user side. Plus, we also needed to validate whether the initial findings would still hold true at scale.
Therefore, we continued to conduct a large-scale survey with the following 3 goals in mind:
- Understand non-users: Why weren’t they using AskDEB? What would make them start?
- Validate or invalidate previous findings and hypothesis: Was it a quality or trust issue? A UX issue? A tech skill gap?
- Find opportunities: where should we focus our efforts in the future?
In July 2025, we sent out a company-wide survey to over 4,000 corporate employees. We sent two identical surveys to both AskDEB users and non-users. And we received 476 responses from 2,423 AskDEB users (19.6% response rate) and 117 responses from total 2,234 non-users (5.24% response rate).
6. The Reveal: A Plot Twist
To our surprise, the survey result were quite different than our early assumptions.
6.1 Trust issue existed, but only for a few users.
Although senior leadership and initial interviews suggested that ChatGPT had better results, the data showed AskDEB was rated as equally reliable across tasks.
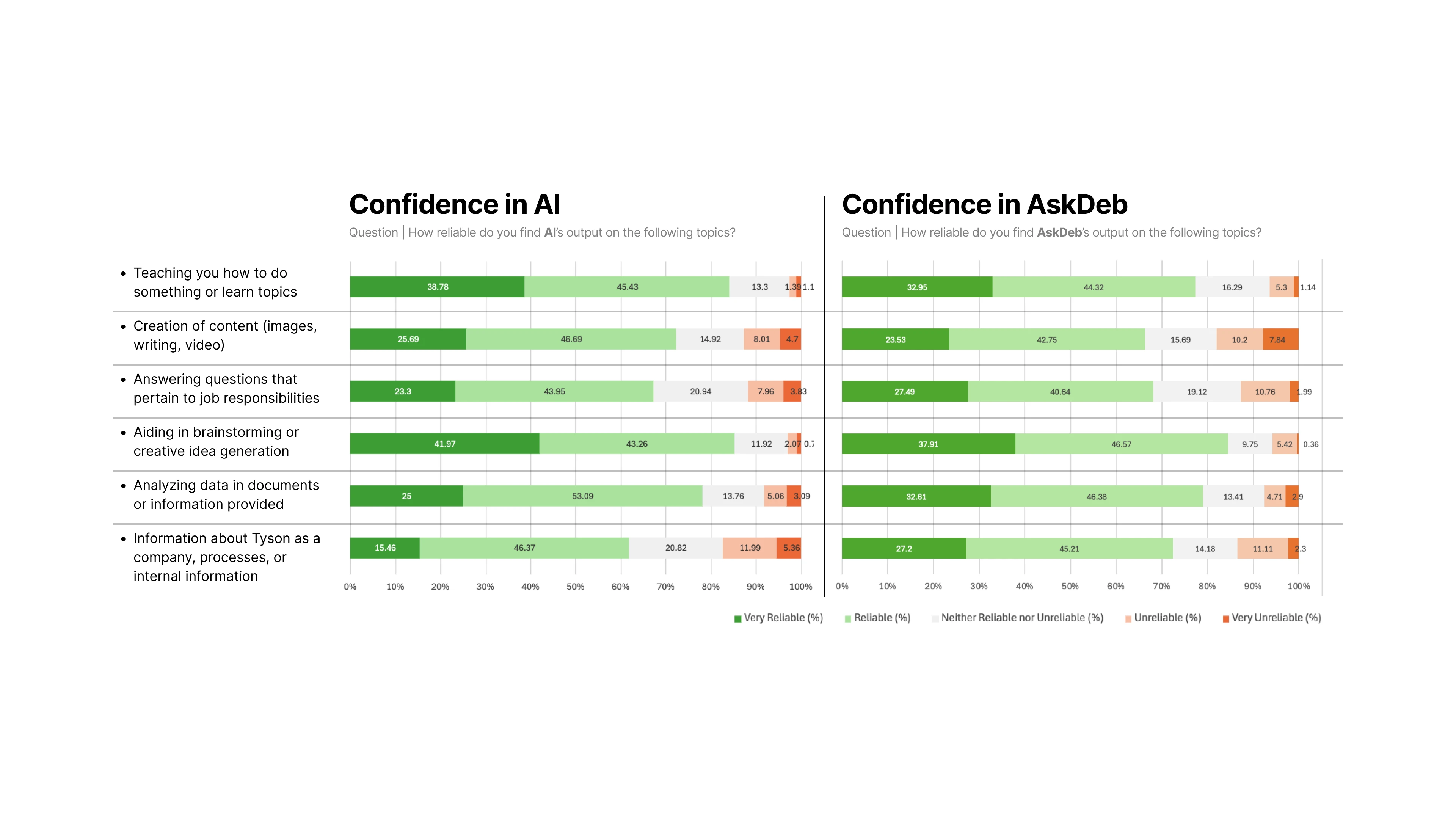 [fig 3] Confidence levels in general AI and AskDEB are very similar across all tasks
[fig 3] Confidence levels in general AI and AskDEB are very similar across all tasks
 [fig 4] Reasons why people never or seldom use AskDEB. Only 13% selected “I don’t trust it”.
[fig 4] Reasons why people never or seldom use AskDEB. Only 13% selected “I don’t trust it”.
6.2 It was not a skill gap.
The data also showed that non-users had the same AI proficiency as active users — they knew how to use AI, they were already using AI, just not AskDEB.
 [fig 5] Non-users have similar AI proficiency as active users.
[fig 5] Non-users have similar AI proficiency as active users.
6.3 UX problems existed but were not the main blocker.
Most users were satisfied and NPS was positive, with only about 30% seeing room for improvements.
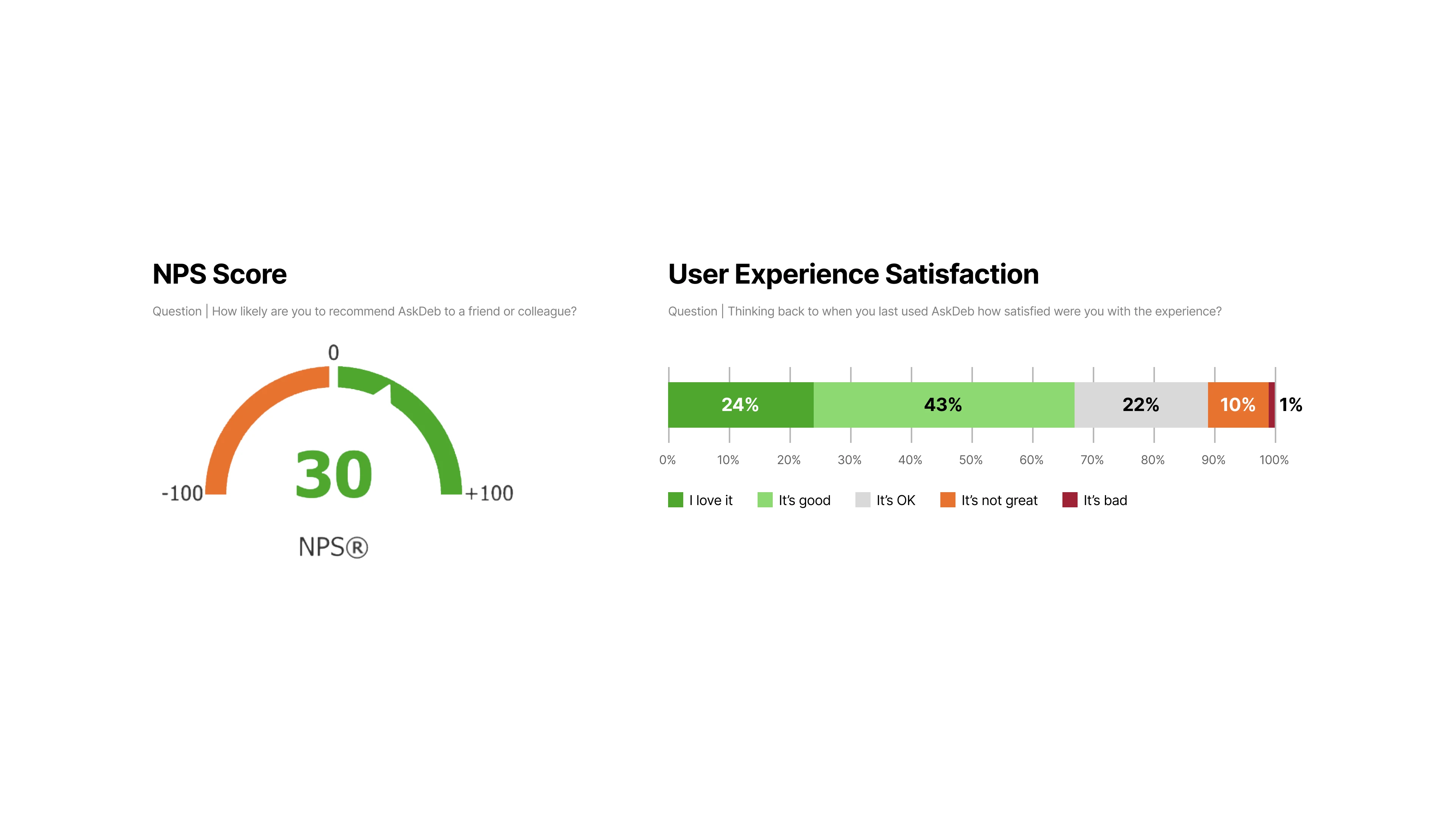 [fig 6] NPS score and User Experience Satisfaction rating for AskDEB.
[fig 6] NPS score and User Experience Satisfaction rating for AskDEB.
6.4 The real barrier — Awareness and relevance.
So why didn’t non-users use AskDEB?
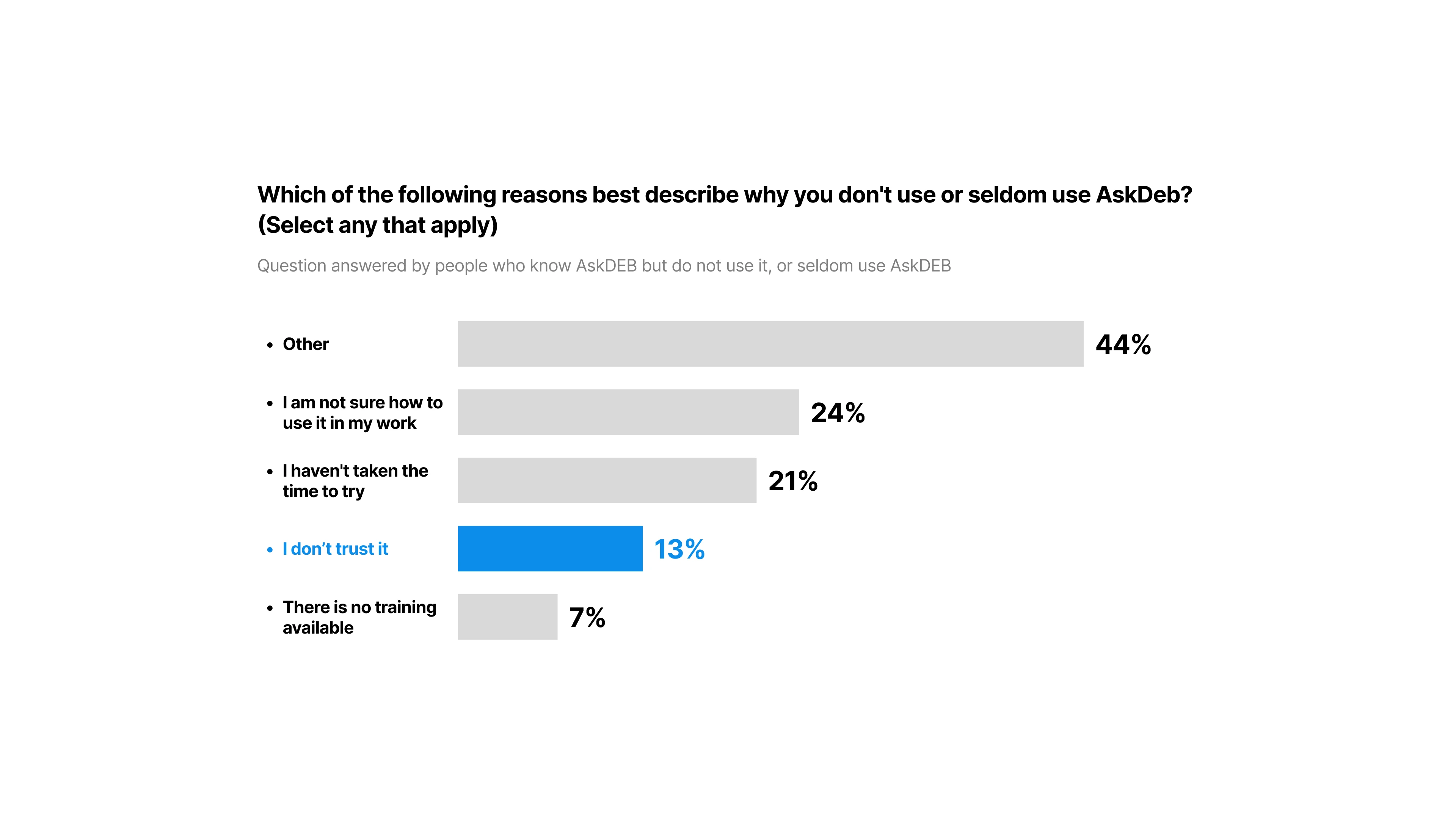
It turned out that 29% of non-users simply didn’t even know AskDEB existed.
And among those who did know it, they didn’t know how to use it in their work 24%, or simple didn’t take the time to try 21%. In other words, AskDEB seems to be irrelevant to them and their work that they weren’t motivated to try it on the first place.
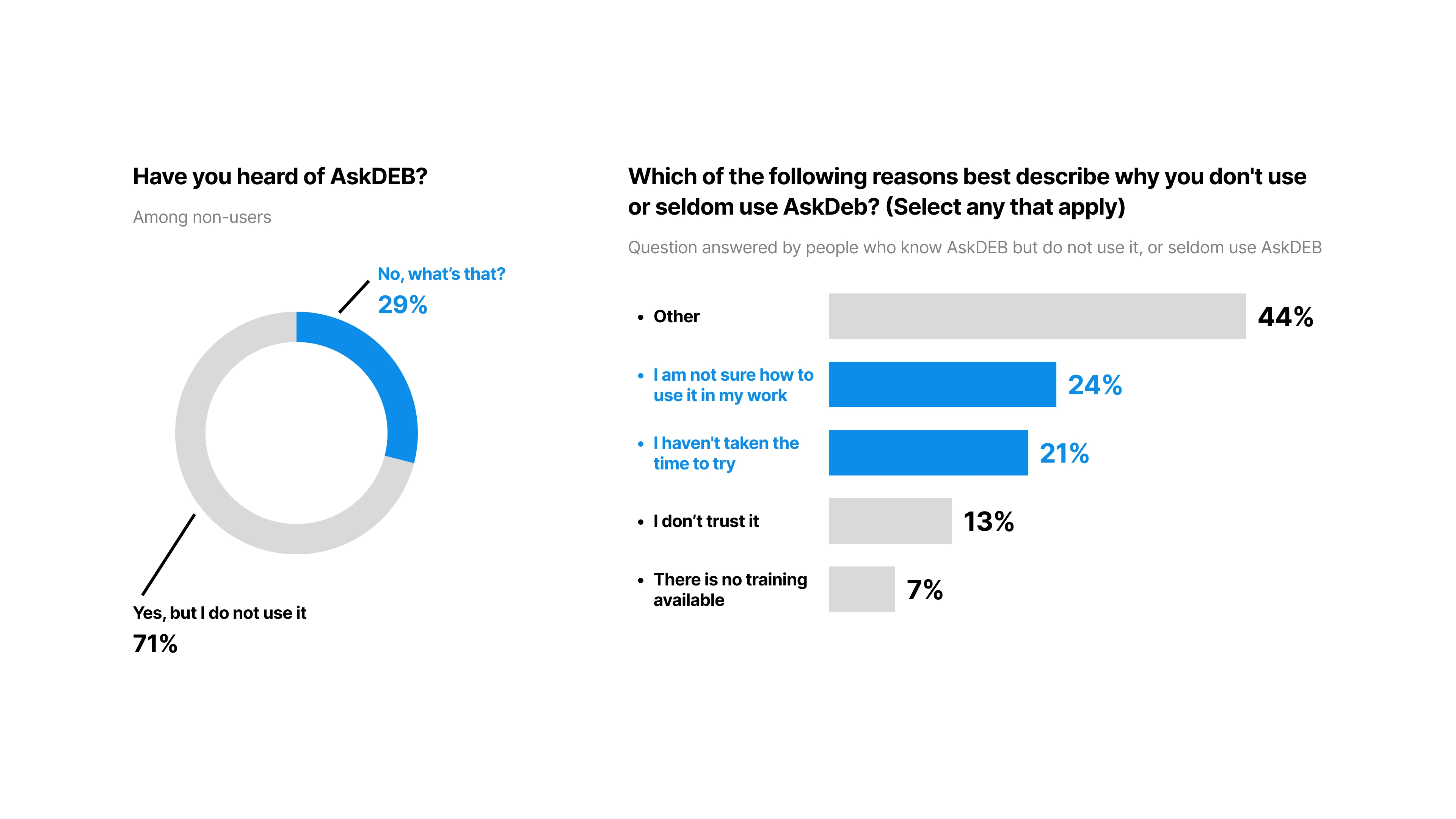 [fig 7] Left: 29% of respondents haven't heard of AskDEB. Right: reasons why respondents who know about AskDEB never or seldom use it.
[fig 7] Left: 29% of respondents haven't heard of AskDEB. Right: reasons why respondents who know about AskDEB never or seldom use it.
Reframe and Next Steps
Now that we learned that the main barrier is not skill, trust, nor usability — it was awareness and relevance. We reframed the problem to be: how to make AskDEB’s value visible?
With this reframed goal and the research findings in mind, we held a feature workshop with stakeholders and came out with the following strategies:
Short-term quick wins: remove friction and make AskDEB visible by default. Remove access request so that AskDEB is available by default. Get AskDEB into new-hire orientation so that everyone know about it from day one.
Mid-term focus: use cases to prove true value. Partner with different departments and build agents that brings true value. This is also where the 3rd phase research will come in — getting into the weeds of people’s daily workflows. One starting example is to pilot with Human Resource Department to build an onboarding knowledge agent to answer questions from new hires.
Long-term strategy: improve output quality and user experience to sustain adoption. This includes improving internal data quality so AskDEB can generate more accurate answers with company data. And continue to refine the user experience to make AskDEB feel as polished as other major tools like ChatGPT.
The Path Forward: Slow Down and Ground in Users
Somewhere along the way, I came to realize that the real problem might be just moving too fast. We built AskDEB and just threw it out there, hoping everyone would just use it. And it turned out they didn’t. So we did the research and found that, instead of moving fast, we should probably take it slower — let users see it, see its value, use it, and only then improve the quality and experience. Adoption will happen naturally if we succeed in making the value visible.
And the way to make that value visible is to really ground the work in users and their real workflows. Instead of chasing state-of-the-art AI features, we need to slow down, sit with users, and see where AI can help in concrete, lived use cases.